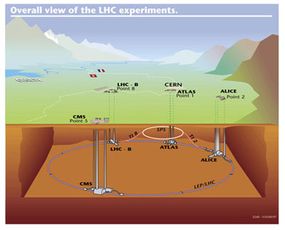
The six areas along the circumference of the LHC that will gather data and conduct experiments are simply known as detectors. Some of them will search for the same kind of information, though not in the same way. There are four major detector sites and two smaller ones.
ATLAS
The detector known as A Toroidal LHC ApparatuS (ATLAS) is the largest of the bunch. It measures 46 meters (150.9 feet) long by 25 meters (82 feet) tall and 25 meters wide. At its core is a device called the inner tracker. The inner tracker detects and analyzes the momentum of particles passing through the ATLAS detector.
Surrounding the inner tracker is a calorimeter. Calorimeters measure the energy of particles by absorbing them. Scientists can look at the path the particles took and extrapolate information about them.
The ATLAS detector also has a muon spectrometer. Muons are negatively charged particles 200 times heavier than electrons. Muons can travel through a calorimeter without stopping — it's the only kind of particle that can do that.
The spectrometer measures the momentum of each muon with charged particle sensors. These sensors can detect fluctuations in the ATLAS detector's magnetic field.
CMS
The Compact Muon Solenoid (CMS) is another large detector. Like the ATLAS detector, the CMS is a general-purpose detector that will detect and measure the subparticles released during collisions. The detector is inside in a giant solenoid magnet that can create a magnetic field nearly 100,000 times stronger than the Earth's magnetic field [source: CMS].
ALICE
Then there's ALICE, which stands for A Large Ion Collider Experiment. Engineers designed ALICE to study collisions between ions of iron. By colliding iron ions at high energy, scientists hope to recreate conditions similar to those just after the big bang. They expect to see the ions break apart into a quark and gluon mixture.
A main component of the ALICE experiment is the Time Projection Chamber (TPC), which will examine and reconstruct particle trajectories. Like the ATLAS and CMS detectors, ALICE also has a muon spectrometer.
LHCb
Next is the Large Hadron Collider beauty (LHCb) detector site. The purpose of the LHCb is to search for evidence of antimatter. It does this by searching for a particle called the beauty quark.
A series of sub-detectors surrounding the collision point stretch 20 meters (65.6 feet) in length. The detectors can move in tiny, precise ways to catch beauty quark particles, which are very unstable and rapidly decay.
TOTal
The TOTal Elastic and diffractive cross section Measurement (TOTEM) experiment is one of the two smaller detectors in the LHC. It will measure the size of protons and the LHC's luminosity. In particle physics, luminosity refers to how precisely a particle accelerator produces collisions.
LHCf
Finally, there's the Large Hadron Collider forward (LHCf) detector site. This experiment simulates cosmic rays within a controlled environment. The goal of the experiment is to help scientists come up with ways to devise wide-area experiments to study naturally occurring cosmic ray collisions.
Each detector site has a team of researchers ranging from a few dozen to more than a thousand scientists. In some cases, these scientists will be searching for the same information. For them, it's a race to make the next revolutionary discovery in physics.
Oops!
Scientists had hoped to bring the LHC online in 2007, but a major magnet failure slowed things down. An enormous magnet built by Fermilab suffered a critical failure during a stress test.
Engineers determined that the failure stemmed from a design flaw that didn't take into account the enormous asynchronous stresses the magnets could endure.
Fortunately for researchers, engineers fixed the flaw fairly quickly. But another one in the form of a helium leak popped up.