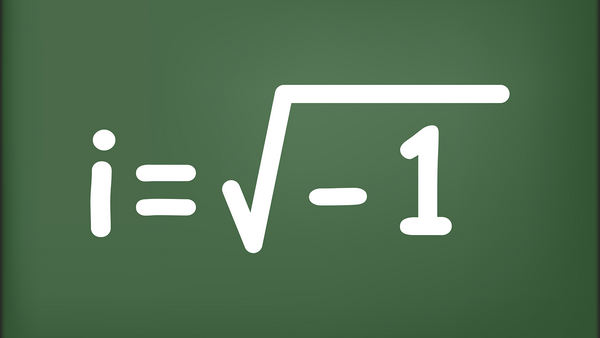The range of a collection of numbers — mathematicians call this a "data set" — is the difference between the highest number and the lowest number in the data set. What is range? Well, it tells you how spread out the numbers in the data set are.
Advertisement